Getting started with sentiment analysis.

I am a Data Scientist, I love telling stories with data. I retrieve data using SQL, clean it, do exploratory data analysis on it to help stakeholders make data informed decisions. I also build and deploy machine learning models, mostly in the fields of finance, e-commerce and Natural Language Processing. I am a lover of python and all you can do with it using frameworks like Flask and fastAPI. I also do front end web development using React, not really a jack of all trades, but a lover of all things tech and being in the know of emerging trends and changes.
Sentiment analysis is an approach to natural language processing (NLP) that studies the subjective information in an expression. When we say subjective information, this means that the information is subject to change from person to person and it includes the opinions, emotions, or attitudes towards a topic, person or entity which people tend to express in written form. These expressions can be classified as positive, negative, or neutral. Machine Learning algorithms review this textual data and extract valuable information from it and then brands and businesses make decisions based on the information extracted.
Here are a few advantages of Sentiment Analysis especially in Business:
It helps you understand your audience and their specific needs.
You can gather actionable data about your products based on critiques and suggestions given by customers.
You can get meaningful insights about your brand and the kind of emotion it invokes among the people.
Conduct a comprehensive competitive analysis and gauge your product against that of your competitor.
Monitoring long-term brand health by tracking sentiments over long periods ensures that you have a positive relationship with your target customers.
It would be very expensive in terms of time and cost to have human beings read all customer reviews to determine whether the customers are happy or not with the business, service, or products. This necessitates the use of machine learning techniques such as sentiment analysis to achieve similar results at a large scale. For example, imagine a large company like amazon going through all reviews they receive about their products one by one, it would take ages and a lot of manpower to do so. A machine learning model would be the best approach in such a scenario.
In this article, you will practically learn how to go about sentiment analysis using Twitter sentiments. By the end of the article, you will have developed a Sentiment Analysis model to categorize a tweet as either Positive or Negative.
The dataset being used can be gotten from Kaggle.com using this link: https://www.kaggle.com/datasets/kazanova/sentiment140
This dataset contains 1,600,000 tweets extracted using the Twitter API and they have been annotated (0 = negative, 4 = positive) and can be used to detect sentiments.
Take note that I have used Jupyter Notebooks.
Make sure all relevant imports are present as shown in the code snippet below:
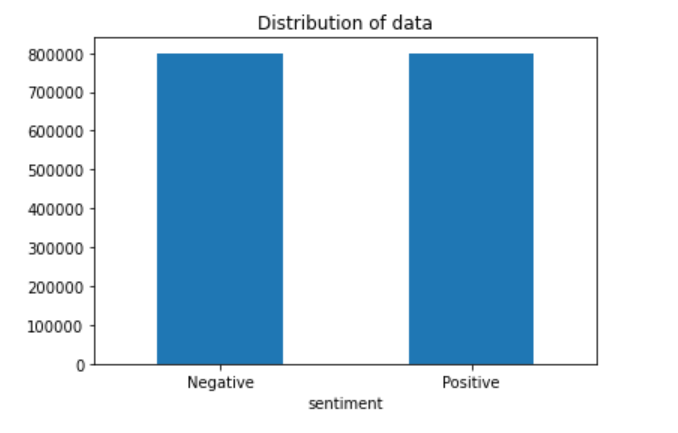
Load the dataset into your notebooks and plot the distribution of the tweets based on whether they are positive or negative as shown:

You should expect the output shown below:
Perform Text Processing which is transforming text into a more digestible form so that machine learning algorithms can perform better.
The Text Preprocessing steps that have been taken are:
Converting each text into lowercase.
@Usernames have been replaced with the word "USER". (eg: "@pierre_wainaina" to "USER")
Characters that are neither numbers nor letters of the alphabet have been replaced with a space.
Replacing URLs: Links starting with "http" or "https" or "www" are replaced by "URL".
Short words with less than two letters have been removed.
Stopwords, which are words that do not add much meaning to a sentence, have been removed. (eg: "a", "she", "have")
Words have been lemmatized. Lemmatization is the process of converting a word to its base form. (e.g: “worst” to “bad”)
Emojis have been replaced by using a pre-defined dictionary containing the emojis and their meaning. (eg: ":)" to "EMOJIsmile")
3 or more consecutive letters have been replaced by 2 letters. (eg: "Heyyyy" to "Heyy")


Analyzing the data
Let's analyze the preprocessed data to get to understand it. Below is code for plotting Word Clouds for Positive and Negative tweets from the dataset and it will give a visual output of the words that occur most frequently.

Below is the output of the word cloud for negative tweets:

Splitting the Data
We shall split the pre-processed data into 2 sets :
Training Data: The dataset on which the model would be trained will contain 95% of the data.
Test Data: The dataset on which the model would be tested against will contain 95% of the data.

TF-IDF Vectoriser
This is a tool that helps determine the significance of words while trying to comprehend a dataset. For example, if a dataset contains an essay about "My Car", the word "a" might appear frequently and have a higher frequency than other words such as "car", "engine", or "horse power". These words however, may carry very important information but have lower frequency as compared to words like "the" or "a".
This is where the TF-IDF method comes into play, which assigns a weight to each word based on its relevance to the dataset.
The TF-IDF Vectorizer transforms a set of unprocessed documents into a matrix of TF-IDF characteristics, and is typically trained only on the X_train dataset.
As seen in the code below, X_train and X_test dataset have been transformed into matrix of TF-IDF Features by using the TF-IDF Vectoriser. These datasets will be used to train and test the model.
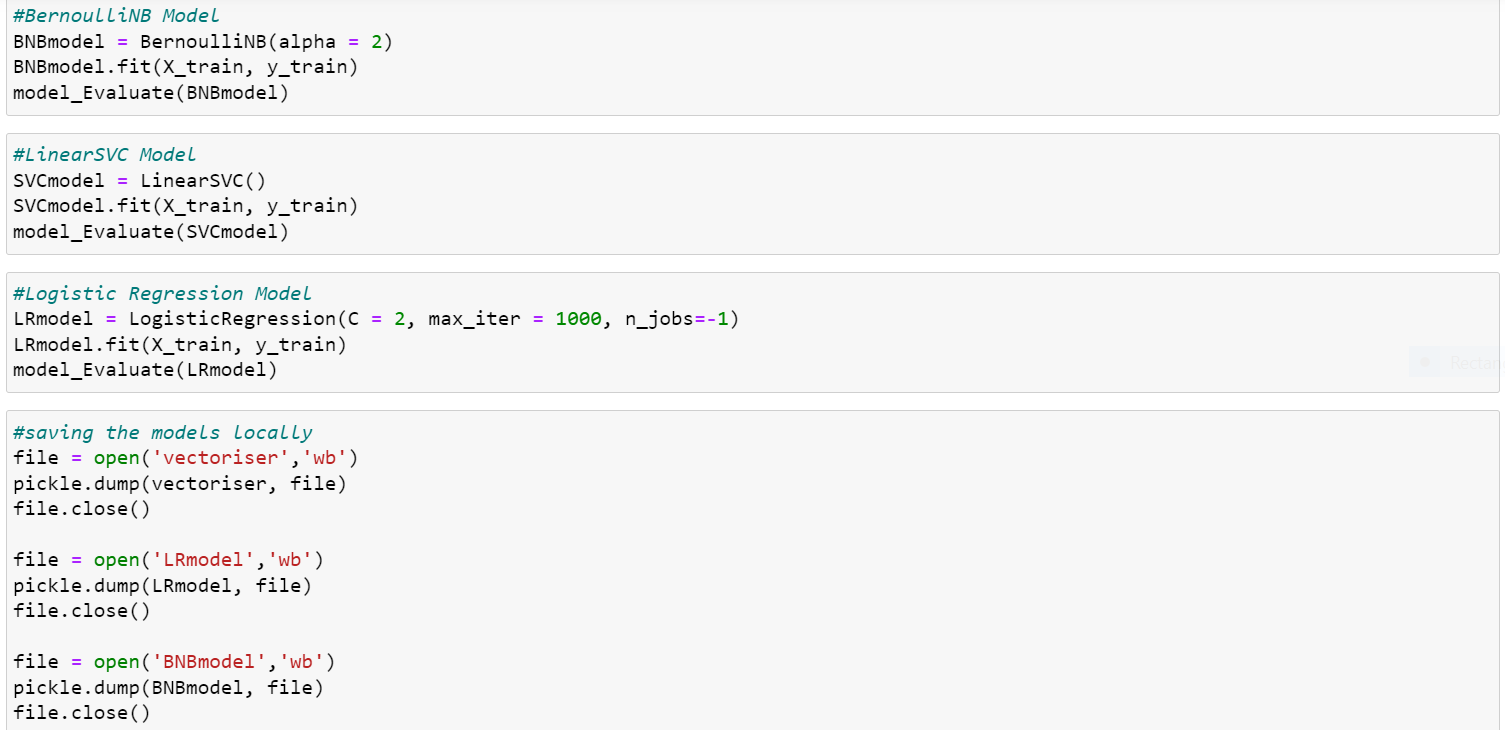
Creating and Evaluating Models
We will create 3 models for our sentiment analysis.
Bernoulli Naive Bayes (BernoulliNB)
Linear Support Vector Classification (LinearSVC)
Logistic Regression (LR)
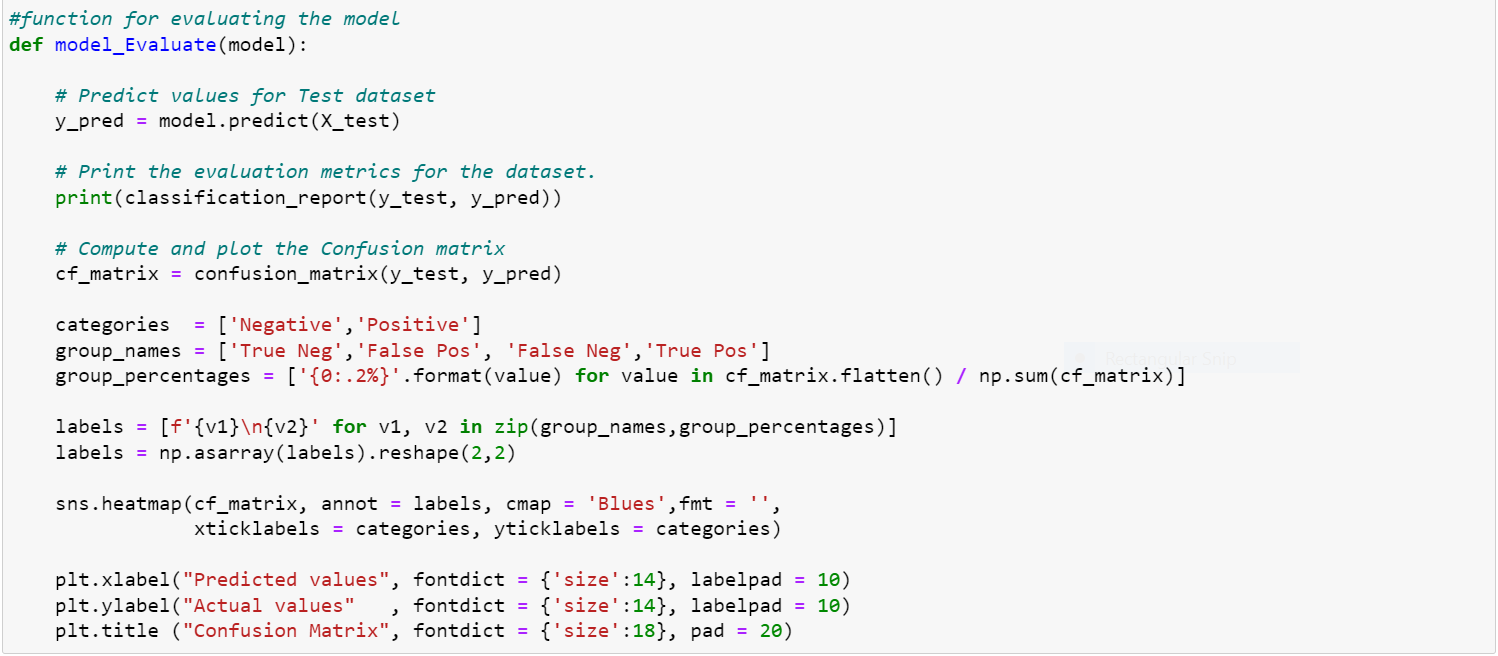
As seen in the very first output, our dataset is not skewed and therefore we choose accuracy as our evaluation metric. We are plotting the Confusion Matrix to get an understanding of how our model is performing on both classification types, either positive or negative as seen in the code below.
We can now test to see if our model can classify the tweets correctly.
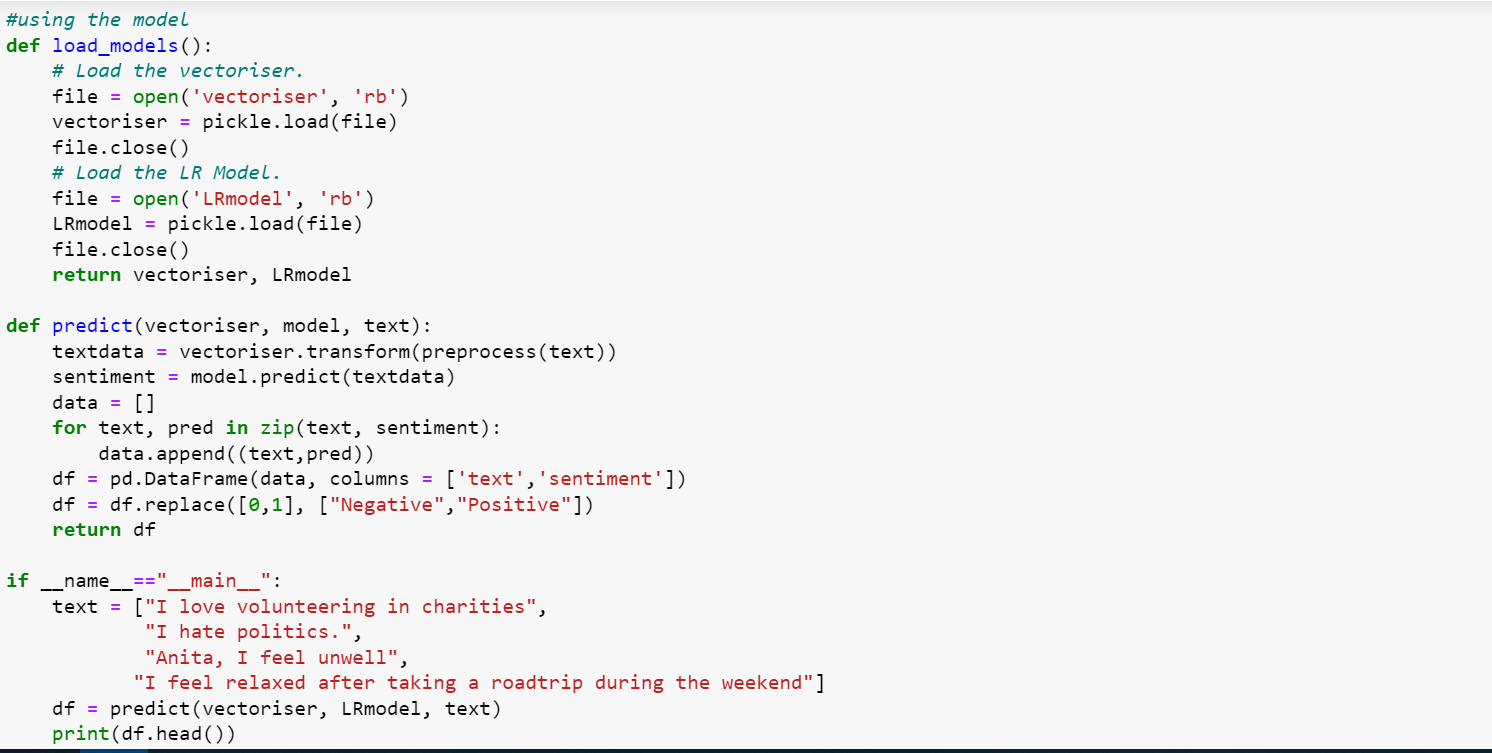
The output should be as follows and our model works well as it can classify tweets as either positive or negative.




